TL;DR — Git is the de-facto distributed version control system used by 95%+ of professional software teams in 2026. Core concepts: repository (your project + history), commit (snapshot of changes), branch (parallel line of development), merge or rebase (combine branches), remote (server copy, typically GitHub/GitLab/Bitbucket). Modern workflows: GitHub Flow (main + short-lived feature branches, used by most SaaS teams), GitFlow (older, main + develop + release branches — fine for versioned releases). For small teams, GitHub Flow + protected main branch + PR reviews is the standard 2026 setup.
One can hardly work and communicate in the digital world without having heard of Git. And there’s GitHub, too – are they the same thing? What are they, even?
Really briefly, Git is a version control system – a program that helps dev teams keep track of the changes made to the source code and work on their pieces simultaneously without stumbling upon each other. But there’s much more to it: keep reading to find out how it works and what good it brings to the workflow.
Skip to:
We’ve been singing praises to Figma for how it facilitates collaboration. But we never got to discussing the means of creating a collaborative environment for developers. How do you keep track of the changes and distribute the tasks effectively? Well, among other things, a well-tuned version control – and version control conducted via Git in particular – serves this exact purpose.
Gladly enough, you don’t have to check, control and bring it all together manually. There are lots of digital solutions for this – they’re called version control systems, or VCSs. Git is one of those; but, first things, first, a few words on what they are and what exactly they do.
Version control systems
A version control system (VCS) is a program for managing changes to the source code. It allows tracking the changes as well as recalling them and reverting to one of the previous states.
By means of a VCS, a team can collaborate on a project and:
- Do it simultaneously without interfering with each other’s work
- Exactly know who’s done what
- Be able to restore the version after applying changes to it.
In development, a VCS helps control the work being done for everyone taking part therein: for the teams, their managers – and for their clients, too.
All VCSs employ a branching approach which means there’s the main bulk of code and the branches with the edits. One developer can work on their part of the task in their branch, leaving the source code intact until approving the changes.
2 types of version control systems
The main types of VCSs stem from the fundamental differences of organizing file storage and, thus, collaboration. You either keep everything somewhere in one place and transfer all your edits there or distribute the storage between computers so that everyone has the whole project. Both these options give us centralized and distributed VCSs, respectively.
Centralized VCS
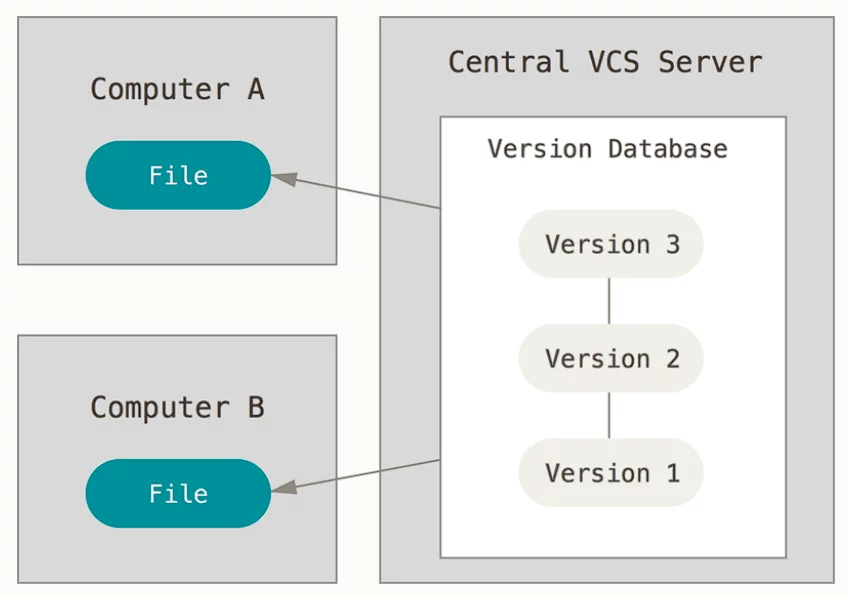
A centralized version control system implies some sort of a center of all your versions. In this case, a center is a server. Everything this system manages resides on one server, and you need to connect to it to edit a project. There are project headquarters, so to say – their center.
In essence, with a CVCS, you have a few client devices (say, desktop computers) and a central server that stores all the information. In some of the systems, clients get to keep only the changes made with them – and not even in the form of an edited copy of the original file. Not a before-after table, not a human-readable file – they store just the patches.
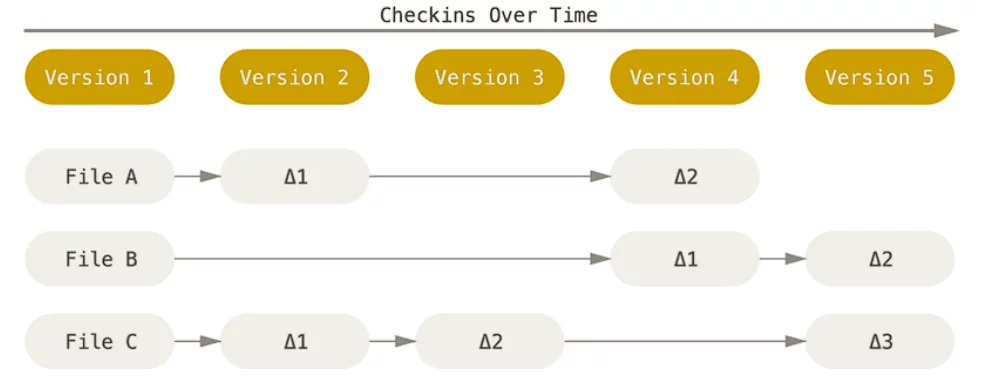
Distributed VCS
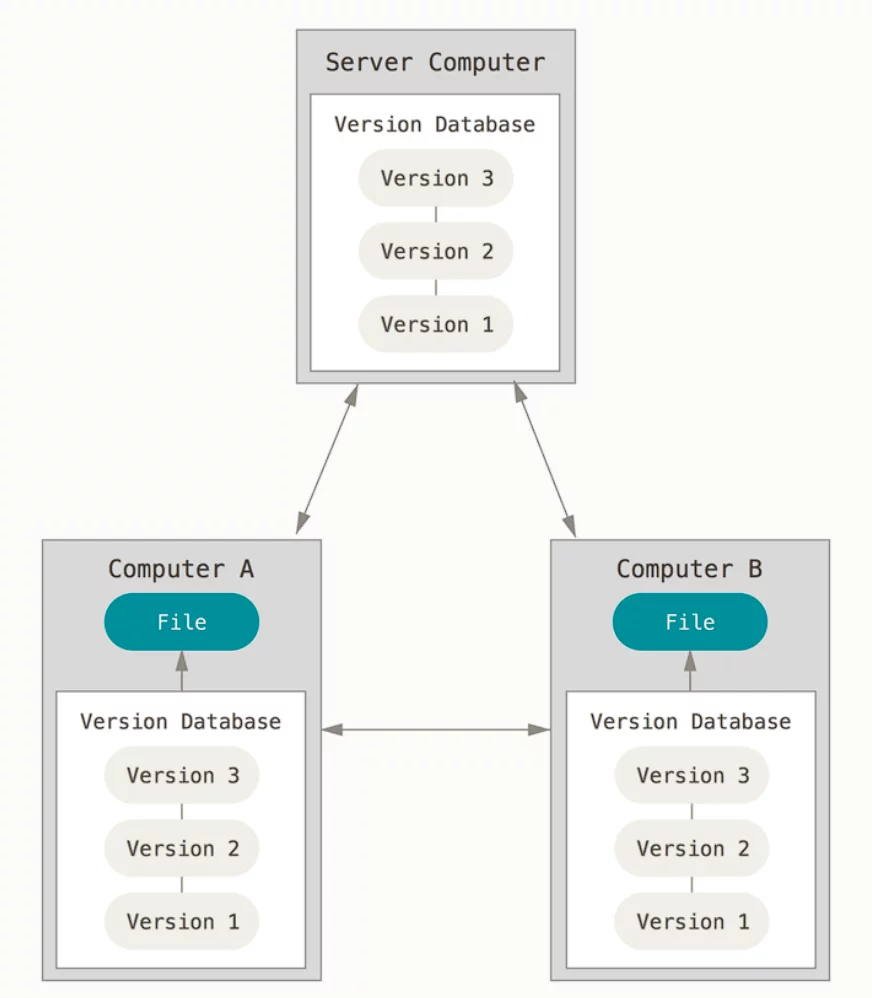
This is the category in which Git falls.
If you’re familiar with peer-to-peer (P2P) connection, you can easily imagine the concept. They’re similar from this standpoint: you don’t need a centralized server for storing the data – every participant is their own server.
Such a system helps leverage the risk of major breaks and data losses since it doesn’t depend on one storage. If the one and only server breaks, it’s a disaster and a corporate tragedy. If one of the many computers that store the same copy breaks, it’s no big deal – you aren’t facing anything much worse than the cost of the device broken and a few person-hours due to production interruption.
Git specifically stores snapshots of files, not patches.
Nerd note: That about storing snapshots is a bit of a simplification, and Git geeks might roll their eyes at that. But it does convey the sense of the matter quite fine. The word snapshot here indicates that it is not the difference between the two versions Git keeps; it’s the version itself. To dig deeper into details, Git stores pointers to the changes and the metadata that come along.
Git version control – Main features

1. Storage distribution
Apart from protection from data loss, the DVCSs’ approach to file storage allows for independent and, therefore, uninterrupted work of different developers on the same project. Parallel working thus allows for workflow acceleration because people don’t have to verbally coordinate their actions and can commit without checking with the rest of the team.
Storage distribution also boosts performance, even though it may seem counterintuitive. You don’t need to load files from the server each time you want to make an edit – you have them on your computer. Also, Git selects whether it should store a commit as a diff or as a snapshot depending on how memory-effective both are.
2. Universal compatibility
Being the most popular version control system, Git can run on any operating system – Linux, macOS, or Microsoft. What’s also nice is that switching to another VCS would be no problem, too. Since Git is known for a slightly steeper learning curve, other systems will be a piece of cake once you get your hands on Git.
Don’t get scared, though: it’s comparatively steeper but not that difficult per se. To get started, you need a few commands and access to Google search. Besides, the commands are similar for most of the VCSs and even become intuitive over time.
3. Easy branching & merging
Of all the VCSs, Git is known to have the easiest merging functionality. You just marriage, and that’s it – simple as that. No waiting for others, no possible conflicts due to the discrepancies in each developer’s code version.
This brings about another advantage of DVCSs. The non-linear development allows for a faster project presentation to the client. If you received revisions and now need to show the updated version of the project, you don’t have to finish all the works. You can just commit and push the branch with those changes the client required and present the resulting program while other team members are working on the rest of it.
4. Sustainability & Performance
Storing the entire project on every computer of the system means using the memory needed for one such project, times however many computers are in this VCS. Arguably, this is not exactly sustainable: all the electricity involved increases the carbon footprint and adds to the energy costs.
However, Git was developed with that in mind. The system minimizes such negative impact by compressing everything in it and using pointers instead of copies whenever possible (as we mentioned earlier, the snapshots of the versions, effectively, are pointers).
Now, the picture is slightly different if we talk performance as in speed of operation. To tell the truth, Git is only relatively fast. Given all the advantages of distributed storage, you also get speed improvements from not needing to stay connected to any other computer.
It can take Git a while to process large files. If that’s a concern for your team, you might want to choose another VCS. However, the developers that root for Git reasonably point out that quality has a priority over speed. After all, you don’t want the job to be done in a second if it’s not correct.
Git vs SVN vs Mercurial
Before people felt the need to distribute the storage of files and their versions, centralized systems were widely in use. One of such is Subversion, commonly abbreviated as SVN. Though Git seems to be the most popular choice, some corporations still favor SVN over Git for its hierarchy and centralized nature: this works well for administrative control.
For making our comparison more representative, let’s take another distributed VCS additionally to Git. Right, as you may imagine, Git isn’t the only DVCS out there. Its close competitor (close maybe not in popularity but in functionality) is Mercurial, AKA Hg.
And on with the comparison!
Costs
All of the three happen to be free and open-source. All you need is a PC where you can install it, a hosting service, and that’s it.
System requirements & Performance

Of course, the heaviness of your system largely depends on what you store in it. But there are differences in storage requirements even for the empty VCSs. Namely, Git itself is 222 MB – and SVN needs a similar amount of disc space, and Mercurial is 64 MB. So, Mercurial is a clear winner here.
SVN tends to perform better with large binary files due to the client-server architecture characteristic of CVCSs. But that same architecture is the reason behind one major drawback: with SVN, one break on the server can destroy the whole project. Since Git and Mercurial don’t store files that way, they’re not susceptible to such dangers.
With SVN, you’re constantly in active interaction with the central server. Logically, that requires a stable connection, thus making the platform internet-dependent and slowing down everyone’s work. On the other hand, with Git and Mercurial, your computer has the entire project; therefore, you don’t need constant internet access. It’s only required for pushing your commits.
Summing up
SVN is behind both Git and Hg in terms of providing an uninterrupted workflow. However, if you’re diligent with backups and create them often enough, you can save yourself from losing all the work. In most cases, Mercurial will be the fastest one, with Git running closely after it.
Clarity

Git advertises its flexibility, but that’s exactly the reason for the lack of clarity in Git’s command line interface (CLI). The platform is notorious for having highly context-dependent commands, which makes Git almost inscrutable at first glance. Even the developers who have been using Git for years don’t know all the commands by heart. But, let’s note that the routine set (used often enough for the commands to stick in your memory) is not that big. And when you do need something rather uncommon, you can look it up.
Giving credit where it’s due, Git is more flexible than other VCSs. Unfortunately, at the price of clarity and the easiness of learning it. Mostly, only the more experienced developers can fully enjoy the benefits of this flexibility while the beginners will struggle through all the ambiguity. So, every team decides for itself whether it’s a pro or con.
Mercurial, on the contrary, is famous for having no such issues. Its CLI is clear even for beginners, and all commands serve one specific purpose. This approach does make you account for all the details, but that’s a fairly reasonable tradeoff, given the necessity for precision in development.
SVN, being a centralized system, allows for a clearer view for the administrators. It can be incredibly helpful in big companies with a strict hierarchy that need to monitor the traffic meticulously. And it also is fairly easy to learn: it’s comparable with Mercurial from this standpoint.
Summing up
Mercurial is the easiest one to use, given its unambiguous CLI and an almost unnoticeable learning curve. SVN is also clear and quite user-friendly for beginners. Git’s CLI represents a sacrifice of clarity in favor of flexibility: beginners won’t find it exceptionally clear, but experienced users might appreciate the benefits that come along.
Merging

The most complicated branching and merging happens to be in SVN. It requires the admins of the system to manage the process to avoid any potential conflicts and errors. We should note that it can help prevent the situation when the source code is changed without the manager knowing. But it does make the process more difficult than with the other two VCSs.
Mercurial and Git conduct merging using different algorithms, but effectively, both provide comparable ease of merging. However, Git allows for the so-called octopus merging, i.e., merging of several branches at the same time. It’s not the most necessary feature in the world, but it can come in handy.
Scalability

All of the more or less widespread version control systems are scalable – at least, to a certain degree. However, neither of the distributed VCSs boasts exceptional scalability. Coming back to Git – it’s not even among the leaders from this standpoint. When it comes to executing commands on a Facebook-size repository, the response time increases up to half a minute.
That’s exactly vice versa with SVN. It’s known to be the best for really big repositories, outperforming both Git and Mercurial. But, with small to medium-sized files, all three will work and scale fine.
Rewriting history

Git provides users the ability to change the history: how fancy does that sound, huh?
What that saying stands for is that Git users can edit the older versions. This feature raises the dilemma of the untouchability of the version history: should you keep everything intact for the clear record or should you keep only what’s correct and necessary?
In Mercurial, you can only abort the previous edits, AKA do the hg rollback. Git allows for much more, but developers argue whether or not it’s ok to change the version history at all. The pro-changers will say: “There could have been errors: should they be kept as well?” But the ones against it
In Mercurial, you technically aren’t able to do it with the system in its default state. But you can do it with extensions like histedit, MQ or collapse. They aren’t innate features but they do the trick and are fairly easy to install and use.
SVN, last but not least, doesn’t allow any non-admins to rewrite history. Once again, that’s due to its centralized nature.
Summing up
Git is more generous and liberal about editing history, but Mercurial also provides means for it. SVN users can’t change anything in the previous versions if they’re not admins. Which is a good thing and which isn’t – up to each team.
Git ≠ GitHub: Not the same, but meant for each other

If you’ve never worked with either, you might confuse one for another or think of them as one and the same. However, even though the two have similar names, their purposes are very different.
Git is a version control system, i.e., the system that helps you edit files and keep the history of all the changes. GitHub, on the other hand, is a cloud-based hosting for git repositories. You can use it for public collaboration and the exchange of professional experience. In other words, it’s a hub for all your Git code, so to speak.
GitHub is also a huge help for the Git novices – and for the experienced ones, too.
If you’re a beginner in web development, you will find it a lot easier to adapt to Git with GitHub.
Version control beginner glossary
Repository – a folder in your project with all the files and the history of all changes (whereto you make commits).
Working tree – the project within your Git repository on which you’re currently working with all the files related to that project.
Master – the default branch of code in a Git project – in other words, your main branch. You can technically change its name, but “Master” is a naming convention.
Branch – a pointer to the change you’ve made to the code.
Commit – the act of saving the changes to the default branch locally. In Git, it consists of the snapshot and metadata; other VCSs use diffs and metadata.
Merge – the act of combining different branches into one unified history.
Push – the act of applying the changes to the default branch
Patch/diff/delta/changeset – the changes made to a branch.
For those who would like to start learning Git more thoroughly, here’s a list of terms and professional slang specific to Git – GitGlossary. It’s a more in-depth scope but it gets a bit more technical than our post.
Final thought
This post is not to scare you with Git’s complications. After all, it’s popular for a reason: developers often prefer it over other options. We in Belov Digital use it, too! With Git, version control is a piece of cake once you get the hang of it. And Git’s learning curve is not too crazy: as we mentioned, all you need for a start is a few commands. But if you still feel insecure about starting with no experience or would like some assistance along the way, check their Try Git guide or look up some courses like the Codecademy’s.